IT Crisis Management Playbook: Effectively Respond To And Mitigate IT Crises
This IT Crisis Management Playbook is a practical, scenario-based guide that helps organizations understand IT crises and respond to them with speed and precision. Its goal is to help prepare organizations to handle unexpected incidents, minimize disruption, and restore critical operations quickly.

Covering cybersecurity breaches, vendor failures, ransomware attacks, and internal outages, this guide uses real-world examples to unpack common causes and effective mitigation strategies. It gives IT teams the clarity and confidence to navigate complex crises and keep the business running.
This playbook is designed for enterprise leaders and teams who play a key role in IT resilience, including:
IT Leadership – CIOs, CTOs, and executives driving overall IT strategy.
Operations Managers – Those overseeing daily IT operations and service delivery.
Compliance Officers – Professionals ensuring regulatory and security adherence.
Security Teams – Experts safeguarding infrastructure and sensitive data.
Executive Stakeholders – Senior leaders who depend on IT for decision-making and business continuity.
Packed with actionable insights, tools, and templates, this guide equips every stakeholder to anticipate threats, respond decisively, and safeguard business continuity in the face of any IT crisis.
Crisis Categories & Real-World Lessons
1. Cybersecurity Breaches (External Attacks)
Cybersecurity breaches are among the most disruptive IT crises for any organization. Attacks by cybercriminals or state-sponsored groups can lead to data theft, financial loss, reputational damage, and even legal exposure.
Common Causes
Unpatched Software – Delayed or missed security updates leave known vulnerabilities open for attackers to exploit.
Weak Application Security – Poor coding practices, inadequate authentication, and lack of input validation expose systems to injection attacks (e.g., SQLi, XSS) and credential abuse.
Limited Threat Monitoring – Without continuous detection, attackers can move laterally for weeks, escalating privileges and exfiltrating data unnoticed.
Real-World Examples:
Equifax (2017): A missed patch in Apache Struts (CVE-2017-5638) allowed attackers to access sensitive data of 147 million people. The breach went undetected for two months, costing Equifax over $700M in settlements and highlighting the high stakes of timely patching and strong detection.
T-Mobile (2021): Attackers exploited a poorly secured test environment and outdated systems to steal data from over 40 million customers. Limited logging and weak segmentation delayed detection, underscoring the need for proactive monitoring and modernized infrastructure.

Mitigation & Response Checklist:
Regular Vulnerability and Patch Management: Establish a strict patching schedule and use tools like Nessus or Qualys to scan for known weaknesses, prioritizing high-severity CVEs.
Secure Software Development Lifecycle (SSDLC): Build security into every development stage through secure coding practices, code reviews, penetration tests, and tools like Web Application Firewalls (WAFs).
Advanced Threat Detection: Deploy SIEM platforms (e.g., Splunk, Microsoft Sentinel) and Endpoint Detection and Response (EDR) tools to monitor anomalies and automate alerts for suspicious activity.
Employee Training & Access Controls: Run regular phishing simulations, enforce multi-factor authentication (MFA), implement strong password policies, and apply least-privilege access to limit insider risk.
Incident Response Planning: Maintain a clear, rehearsed Incident Response Plan (IRP) with defined roles, escalation paths, and cross-team coordination for legal, PR, and executive communications.
2. Vendor-Related Breaches
As enterprises scale, they increasingly depend on third-party vendors for software, cloud services, and operational support. While these partnerships drive efficiency and innovation, they also introduce new cybersecurity risks. A vendor-related breach occurs when attackers exploit vulnerabilities in a partner’s systems or misuse their authorized access to an organization’s internal network. Because vendors often have trusted, integrated connections, these breaches can bypass direct security controls and cause outsized damage.
Common Causes:
Insufficient Third-Party Oversight – Many organizations assume vendors follow strong security practices without verifying compliance, creating a false sense of security.
Weak Access Controls – Vendors often require privileged access to internal systems. Without strict permissions, monitoring, or time limits, compromised vendor credentials can become an easy entry point for attackers.
Real-World Examples:
Target (2013): Attackers infiltrated Target’s payment systems through a third-party HVAC contractor’s stolen credentials, stealing credit card data from over 40 million customers. The breach highlighted the need for vendor access restrictions and strong network segmentation.
Delta Airlines (2017): Hackers compromised a third-party chat service provider, [24]7.ai, enabling theft of customer payment data on Delta’s website. Though Delta itself wasn’t directly breached, the reputational and financial fallout was significant.
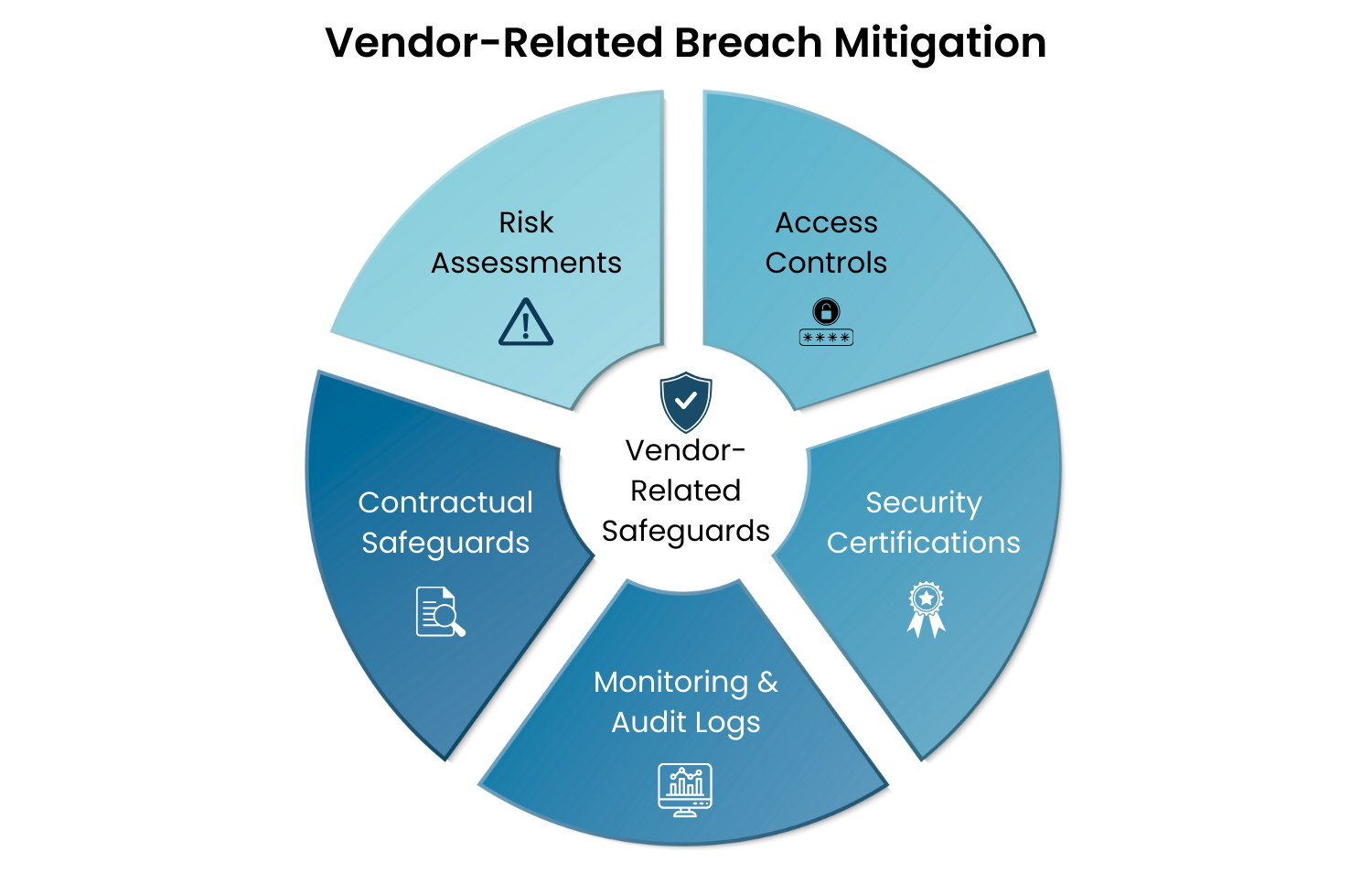
Mitigation & Response Checklist:
Third-Party Risk Assessments: Conduct thorough security reviews before onboarding vendors, including questionnaires, penetration tests, and continuous risk scoring.
Least-Privilege Access Controls: Grant vendors only the minimum access needed for their role and enforce time-limited credentials to reduce lateral movement risk.
Security Certifications: Require proof of compliance with standards such as SOC 2 Type II or ISO 27001, and conduct periodic audits to validate claims.
Continuous Monitoring & Audit Logs: Track and log all third-party activity, reviewing audit trails regularly to spot abnormal behavior early.
Contractual Safeguards: Include security SLAs, breach notification requirements, and data protection obligations in vendor contracts to enforce accountability and expedite incident response.
3. Ransomware and Critical Infrastructure Threats
Ransomware has become one of the most disruptive cyber threats facing enterprises today. These attacks encrypt files or entire systems and demand payment, often in cryptocurrency, for their release. The stakes are especially high for critical infrastructure operators and enterprises where uptime is essential, as a single infection can halt operations, disrupt supply chains, and inflict massive financial and reputational damage.
Common Causes:
Weak Endpoint Protection: Outdated or ineffective antivirus tools struggle against modern ransomware that uses stealthy tactics such as fileless execution, LOLBins (living-off-the-land binaries), and polymorphic code.
Poor Network Segmentation: Flat network architectures allow attackers to move laterally, spreading ransomware rapidly across servers, databases, and critical systems.
Inadequate Backup Strategy: Unverified or poorly secured backups can be encrypted alongside production data, leaving organizations with no recovery option other than paying the ransom.
Real-World Examples:
Maersk (2017): The NotPetya ransomware crippled Maersk’s global shipping operations, shutting down email, port terminals, and logistics systems. The lack of network segmentation enabled rapid spread, with losses exceeding $300 million.
Colonial Pipeline (2021): Attackers gained access through a single compromised VPN account without multifactor authentication, forcing a six-day shutdown of the largest U.S. fuel pipeline. The incident caused regional fuel shortages and highlighted the need for strong authentication and hardened infrastructure.
Mitigation & Response Checklist:
Segment Critical Networks: Isolate sensitive systems by department or function to contain infections. Use micro-segmentation and software-defined perimeters for enhanced control.
Maintain Immutable, Tested Backups: Store backups offline or in immutable formats and test them frequently to ensure reliable recovery.
Deploy Endpoint Detection & Response (EDR): Platforms like CrowdStrike, SentinelOne, or Microsoft Defender provide continuous monitoring, early threat detection, and automated quarantine to stop ransomware before it spreads.
Create and Drill a Ransomware Response Plan: Develop a dedicated response playbook covering containment, communication, legal consultation, and decision-making around ransom demands. Conduct regular tabletop exercises with IT, legal, PR, and executive teams to ensure swift, coordinated action during an attack.
4. Internal Failures & Human Error
While ransomware and supply chain attacks dominate headlines, the most common source of IT crises remains internal mistakes. Misconfigurations, poor data handling, weak internal controls, and simple human error can cause outages, data loss, compliance violations, and reputational damage, often without any malicious intent.
Common Causes:
Inadequate Change Management: Changes to systems or configurations made without proper planning, review, or rollback procedures often trigger outages. Fast-moving environments that prioritize speed over documentation are especially vulnerable.
Poor Data Governance: Without clear policies for data classification, access, retention, and disposal, employees may mishandle or inadvertently share sensitive information.
Weak Backups and Access Controls: Insufficient backups or poorly enforced access policies can turn small errors into major crises. Unverified backups may fail during recovery, while “privilege creep”, employees accumulating unnecessary permissions, raises the risk of accidental or malicious misuse.
Real-World Examples:
GitLab (2017): A system administrator attempting to fix a performance issue accidentally deleted a critical production directory, erasing 300 GB of live data. Multiple backup failures left only a partial recovery point six hours old, exposing gaps in change management and backup testing.
Facebook (2021): A routine configuration update caused a cascading outage that took Facebook, Instagram, and WhatsApp offline for nearly six hours. Internal tools and security systems were also disabled, locking employees out of buildings and delaying recovery. The incident highlighted how even tech giants can suffer massive disruptions from a single misstep.
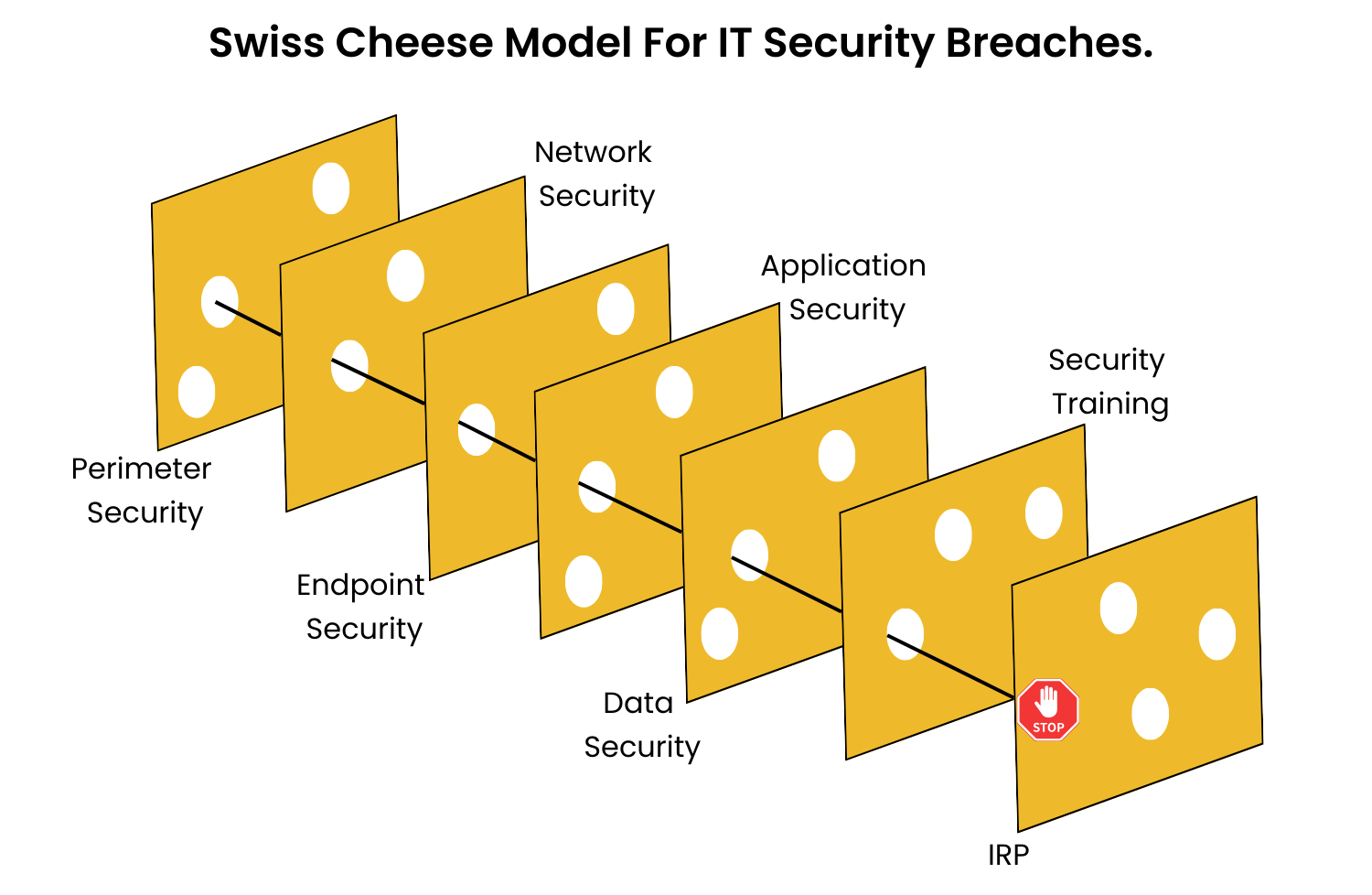
Mitigation & Response Checklist:
Enforce Role-Based Access and Logging: Apply the principle of least privilege to limit user permissions and maintain detailed audit logs to quickly trace incidents.
Adopt Structured Change Management: Require formal change requests, impact assessments, approvals, and rollback plans for all production changes. Tools like ServiceNow, Jira Service Management, or Git-based CI/CD pipelines can streamline this process.
Automate and Test Backups: Schedule frequent, automated backups and regularly test restoration to confirm that both data and configurations can be recovered quickly and reliably.
Invest in Employee Training: Provide ongoing training on data handling, security best practices, and compliance requirements to build a culture of caution and accountability.
Tools & Templates
A well-planned strategy is only half the battle; effective crisis response requires ready-to-use tools that guide actions when pressure is high. The following resources help teams act quickly, reduce errors, and stay aligned across technical, legal, and business functions.
1. Incident Response Flowchart
A visual roadmap for every stage of a crisis: detection, analysis, containment, eradication, recovery, and post-incident review.
Identifies escalation points, decision makers, and next steps to reduce ambiguity.
Supports quick severity assessments and coordinated action across teams.
Can be printed or integrated into platforms like Jira or ServiceNow.
Tip: Add RACI (Responsible, Accountable, Consulted, Informed) roles to clarify ownership at each step.
2. Crisis Communication Template
Pre-approved messaging frameworks for internal teams, customers, regulators, and the media.
Covers incident acknowledgment, known facts, actions taken, and next steps.
Customizable for events such as outages, breaches, or ransomware attacks.
Aligns IT, legal, and PR to deliver clear, consistent updates and protect brand reputation.
Tip: Store securely with version control to ensure quick access during emergencies.
3. Breach Notification Checklist
A compliance tracker to meet regulatory disclosure requirements (e.g., GDPR, HIPAA, CCPA).
Guides timely reporting to users, regulators, and law enforcement.
Includes legal review checkpoints and data-classification filters.
Reduces the risk of fines, penalties, and reputational harm.
Tip: Review with legal counsel and update regularly to reflect evolving regulations.
4. Vendor Risk Assessment Form
A standardized evaluation of third-party security posture; critical for managing supply chain risk.
Reviews data access policies, compliance certifications (SOC 2, ISO 27001), and incident response capabilities.
Helps enforce minimum security expectations during onboarding and renewal.
Tip: Automate annual reassessments with tools like Drata, Vanta, or OneTrust for continuous oversight.
5. Backup and Restore Runbook
An operational guide for maintaining and recovering critical systems during a crisis.
Details backup frequency, retention policies, storage locations, and restoration steps.
Includes verification procedures to confirm backup integrity before full recovery.
Assigns roles and alternate contacts to ensure continuity if key personnel are unavailable.
Tip: Test this runbook regularly during tabletop exercises or disaster recovery drills to validate readiness.
This blog post is an excerpt from our comprehensive guide, Enterprise IT Crisis Management Playbook: A Practical Guide For Businesses To Respond To And Mitigate IT Crises. It additionally includes Crisis Response Frameworks, Ongoing Preparedness Strategies, and more real-world examples.
Conclusion
An IT Crisis Management Playbook is a strategic guide that helps you navigate the complex landscape of technology disruptions with confidence. It outlines a proactive, structured approach to managing a broad range of IT incidents, from cybersecurity breaches and system outages to third-party vendor failures and compliance violations.
By investing in strong IT crisis management practices, your organization can reduce downtime, safeguard data, protect reputation, and maintain operational continuity under pressure.
Don’t wait for a crisis to expose the gaps in your IT defenses. Let's make your business resilient by design, not just by reaction. Contact us today to schedule a Crisis Readiness Audit or request tailored implementation support.










About The Author

Hari SubediMarketing Manager at Jones IT
Hari is an online marketing professional with a focus on content marketing. He writes on topics related to IT, Security, and Small Business. He is also the founder and managing director of Girivar Kft., a business services company located in Budapest, Hungary.